April 2013
Real time visualization of 3D vector field with CUDA
6 Visualization using stream surfaces
Code listing 1: Simplified CUDA kernel for triangulation of stream line pair to stream surface.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 | __global__ void computeStreamSurfaceKernel(uint2* linePairs, uint linePairsCount, float3* lineVertices, uint verticesPerLine, uint* lineLengths, uint3* outFaces, uint* outFacesCounts, float3* outNormals) { uint id = __umul24(blockIdx.x, blockDim.x) + threadIdx.x; if (id >= linePairsCount) { return; } uint2 currPair = linePairs[id]; uint2 lengths = make_uint2(lineLengths[currPair.x], lineLengths[currPair.y]); if (lengths.x < 2 || lengths.y < 2) { outFacesCounts[id] = 0; return; // Lines too short for triangulation. } uint line1Offset = currPair.x * verticesPerLine; uint line2Offset = currPair.y * verticesPerLine; float3* line1 = lineVertices + line1Offset; float3* line2 = lineVertices + line2Offset; float3* normals1 = outNormals + line1Offset; float3* normals2 = outNormals + line2Offset; uint maxFaces = verticesPerLine * 2 - 2; uint3* faces = outFaces + id * maxFaces; uint2 currIndex = make_uint2(0, 0); uint faceId; for (faceId = 0; faceId < maxFaces; ++faceId) { if (currIndex.x + 1 >= lengths.x || currIndex.y + 1 >= lengths.y) { break; // Reached the end of stream line. } float dist1 = (currIndex.x + 1 < lengths.x) ? length(line1[currIndex.x + 1] - line2[currIndex.y]) : (1.0f / 0.0f); // Infinity. float dist2 = (currIndex.y + 1 < lengths.y) ? length(line1[currIndex.x] - line2[currIndex.y + 1]) : (1.0f / 0.0f); // Infinity. uint newVertexIndex; float3 newVertex; uint2 nextIndex; if (dist1 <= dist2) { newVertexIndex = line1Offset + currIndex.x + 1; newVertex = line1[currIndex.x + 1]; nextIndex = make_uint2(currIndex.x + 1, currIndex.y); } else if (dist2 < dist1) { newVertexIndex = line2Offset + currIndex.y + 1; newVertex = line2[currIndex.y + 1]; nextIndex = make_uint2(currIndex.x, currIndex.y + 1); } faces[faceId] = make_uint3(line1Offset + currIndex.x, line2Offset + currIndex.y, newVertexIndex); float3 normal = cross(line1[currIndex.x] - line2[currIndex.y], newVertex - line2[currIndex.y]); normal = normalize(normal); normals1[currIndex.x] = normal; normals2[currIndex.y] = normal; currIndex = nextIndex; } outFacesCounts[id] = faceId; } |

Stream surface (1) 
Stream surface (2) 
Stream surface (3) 
Stream surface (4) 
Stream surface (5) 
Stream surface (6)






Figure 1: Image sequence of stream surface seeded at different places.
6.1 Adaptive stream surfaces

Adaptive triangulation detail.

Figure 2: Adaptive triangulation detail.

Adaptive stream surface (1) 
Adaptive stream surface (2) 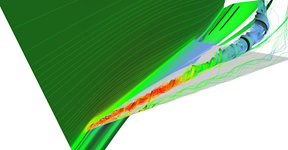
Adaptive stream surface (3) 
Adaptive stream surface (4) 
Adaptive stream surface (5) 
Adaptive stream surface (6)






Figure 3: Results of adaptive stream surface seeding.
6.2 Regular vs. adaptive seeding

Regularly seeded stream surface wireframe mesh 
Adaptively seeded stream surface wireframe mesh
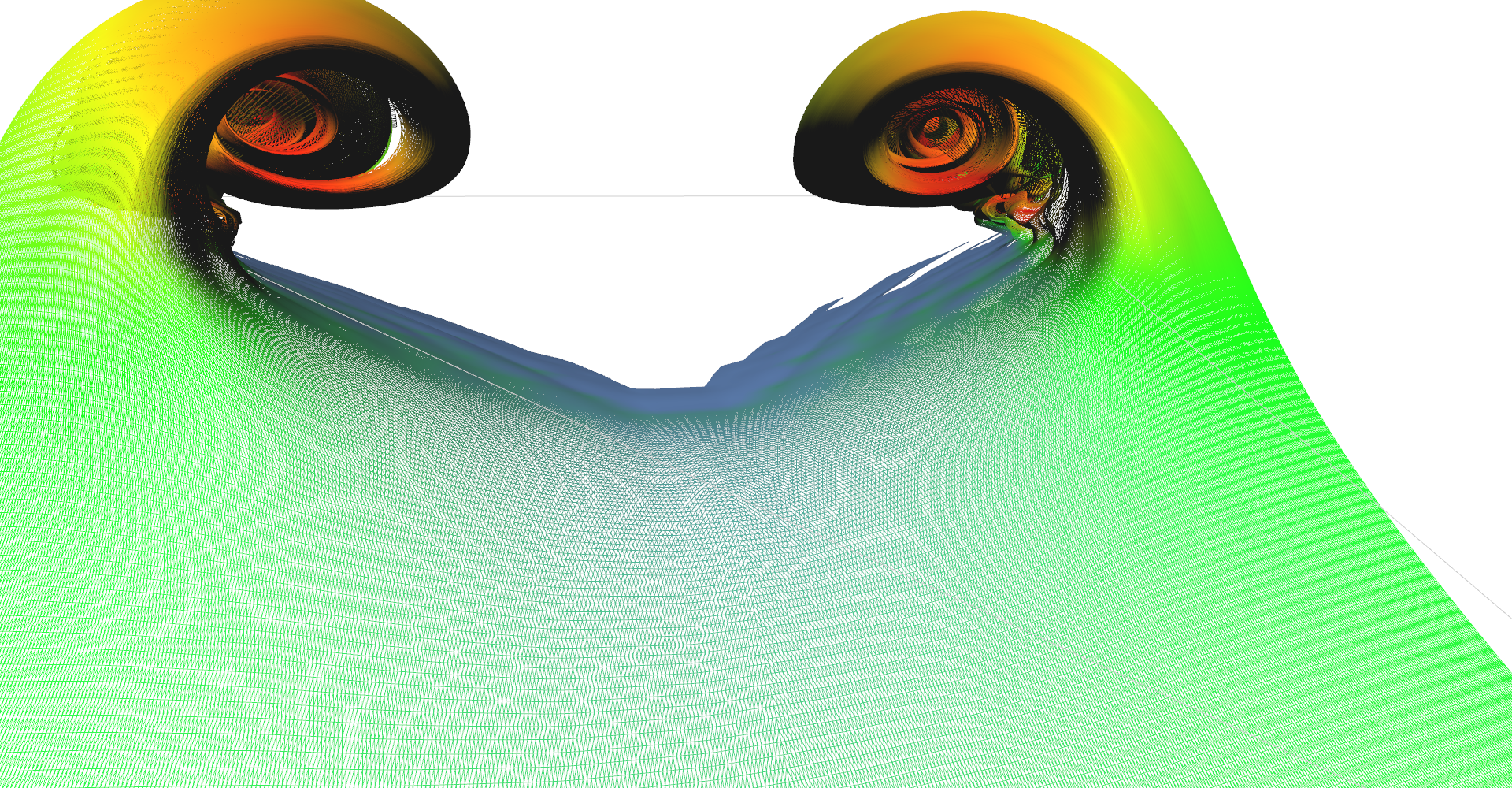

Figure 5: Comparison of wireframe mesh of regularly and adaptively seeded stream surface.

Regularly seeded stream surface (pair 1) 
Adaptively seeded stream surface (pair 1) 
Regularly seeded stream surface (pair 2) 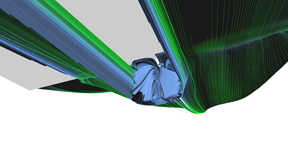
Adaptively seeded stream surface (pair 2) 
Regularly seeded stream surface (pair 3) 
Adaptively seeded stream surface (pair 3)





