April 2013
Real time visualization of 3D vector field with CUDA
7 Performance benchmark
7.1 Hardware
7.2 Comparison of Euler and RK4 integrators
After comparing results visually (see Figure 1), I had to admit that my friend was right. Euler tends to escape vortices even for very low time step values but RK4 does much better job. Interestingly enough, RK4 sometimes converge to the center of vortices instead of escaping them. I did not perform any measurement of the error because the visuals were enough for me to admit that RK4 does much better job than Euler.

Euler integrator for dt=2^-12 
RK4 integrator for dt=2^-12 
Euler integrator for dt=2^-10 
RK4 integrator for dt=2^-10 
Euler integrator for dt=2^-8 
RK4 integrator for dt=2^-8 
Euler integrator for dt=2^-6 
RK4 integrator for dt=2^-6 
Euler integrator for dt=2^-4 
RK4 integrator for dt=2^-4 
Euler integrator for dt=2^-3 
RK4 integrator for dt=2^-3












Figure 1: Comparison between Euler (top) and RK4 (bottom) integrators.
7.3 Glyphs
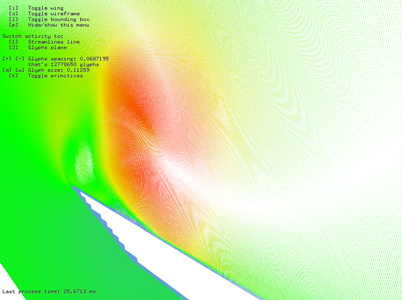
Nearly 13 million of glyphs computed in 26 ms.
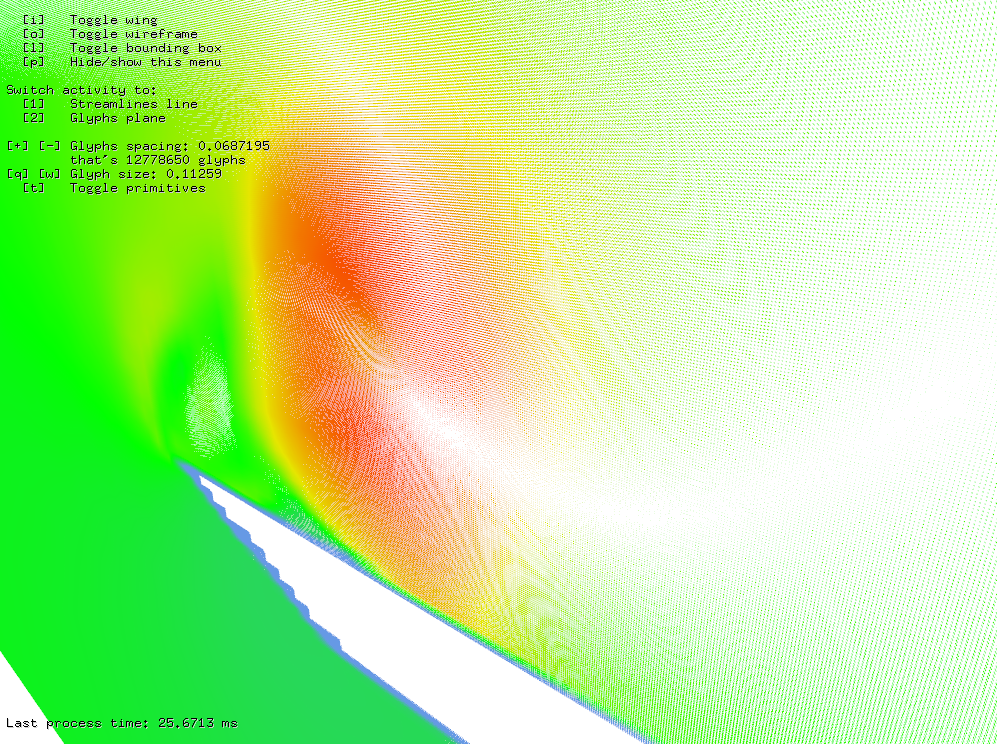
Figure 2: Nearly 13 million of glyphs computed in 26 ms.
7.4 Stream lines and tubes

215 stream lines for 212 steps took 183 ms. 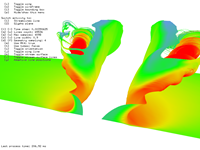
216 stream lines for 212 steps took 207 ms. 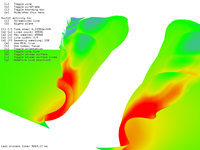
216 stream lines for 216 steps took 8 s.


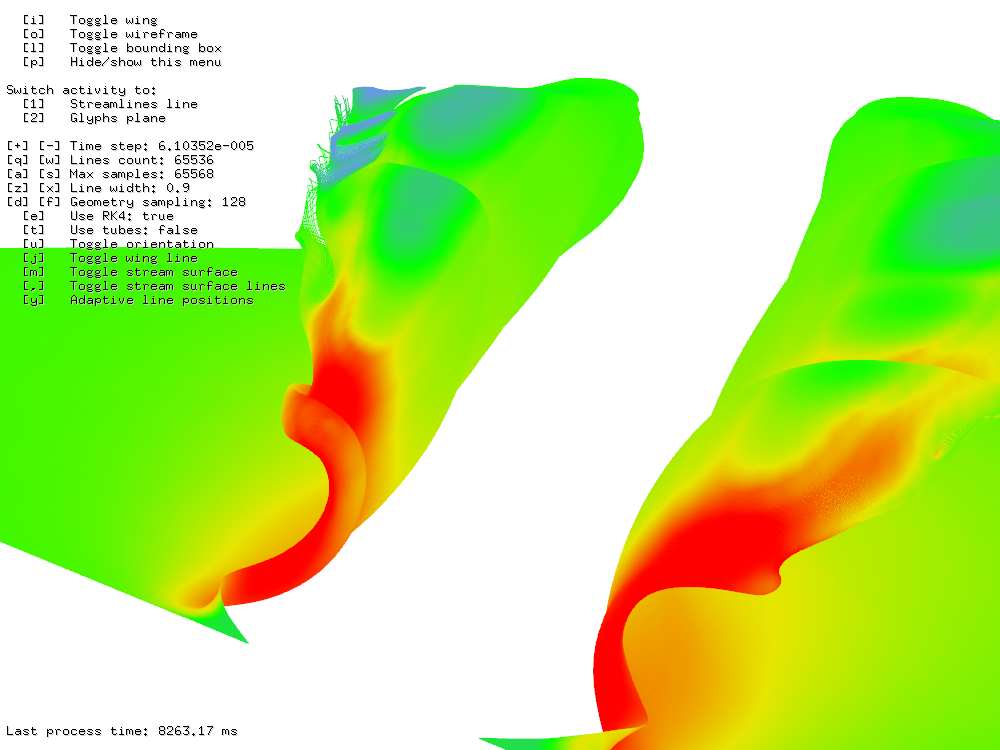
Figure 3: Stream lines benchmark.

215 stream lines for 212 steps using adaptive algorithm took 450 ms.

Figure 4: 215 stream lines for 212 steps using adaptive algorithm took 450 ms.

213 stream tubes for 213 steps took 240 ms.

Figure 5: 213 stream tubes for 213 steps took 240 ms.
7.5 Stream surface
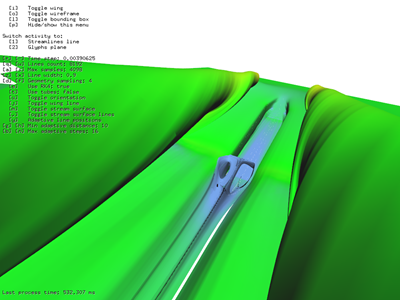
213 seeds for 212 steps using adaptive algorithm took 532 ms.
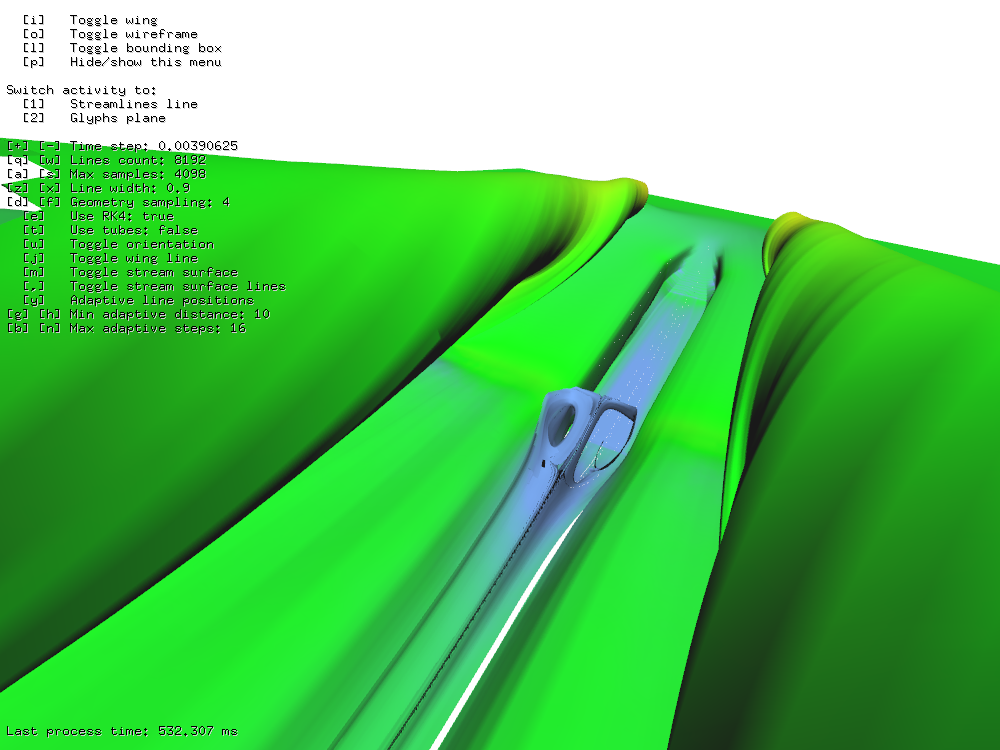
Figure 6: 213 seeds for 212 steps using adaptive algorithm took 532 ms.
7.6 Extra
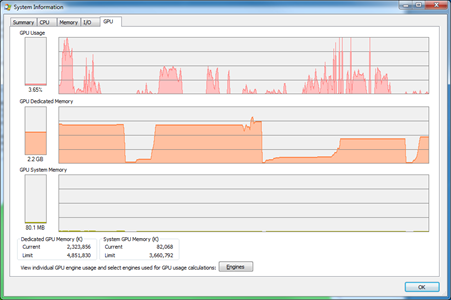
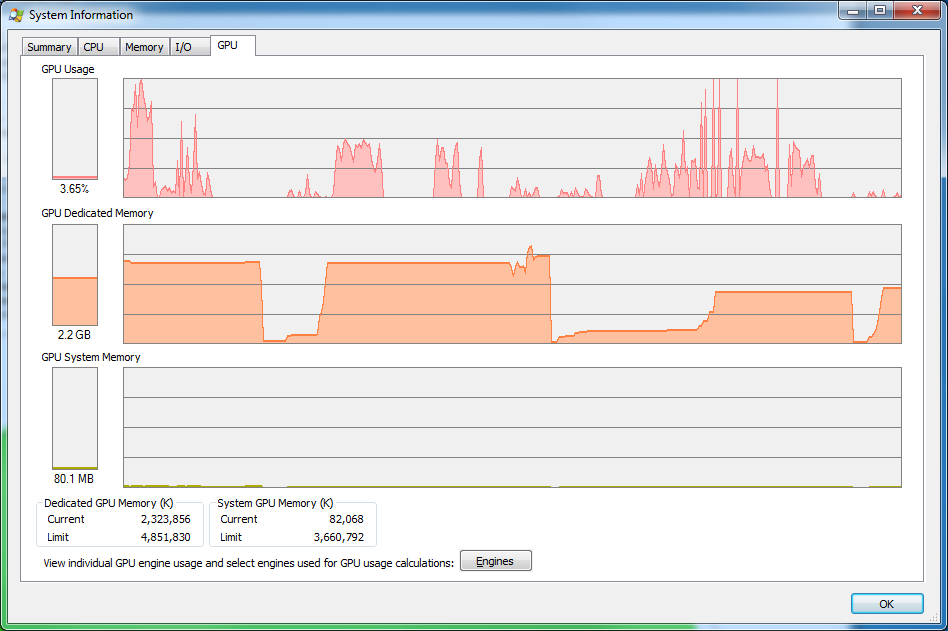
Process Manger GPU card while working with program.